The Conservatives recruited Carol Vorderman to head a ‘mathematics task force’ before the election, in 2009. After the election, in August 2011, the ‘task force’ reported (Telegraph article / Original Report). I find it a little bit puzzling that Vorderman was selected for this, as she is neither a teacher nor a mathematician. (She only managed a 3rd in each of her years at Cambridge studying Engineering.) Nevertheless, the bulk of the work was done by Roger Porkess, it appears, who is head of MEI. He is good.
The report has some good points in it. Nevertheless, page 52 is interesting. It shows three exam questions from previous papers, and the following remark:
Our conclusion from looking at the papers from these three years is that O level was harder than what came before or after it. However, a comparison is not entirely fair because GCSE is designed for a very wide range of students: O levels were not. Discussion of the standard of this, or any other, qualification needs to take place in the context of its fitness for purpose. However, there is compelling evidence that grade inflation has occurred.
The questions are as follows:

(In what follows I will answer the questions. This is probably fairly pointless, as if you read this blog you can almost definitely do them yourself.)
I think the 2011 GCSE question is actually pretty good as approximating an expression is a useful, practical skill which is not so mechanical. Presumably, this was a question in an exam without a calculator. (At least when I did the exam, there was a non-calculator exam and a calculator based one.)
If I were to answer the question, I would multiply the fraction  ‘top and bottom’ by 100, and approximate 95.9 as 100, to give
‘top and bottom’ by 100, and approximate 95.9 as 100, to give  . The product in the denominator is then approximately
. The product in the denominator is then approximately  and thus you get
and thus you get  , as required.
, as required.
I consider that a fairly good, practical problem. It’s much shorter than the other two questions, but this can be attributed to a change of style.
The 1971 O Level question is not as good in my opinion. The first part is, I suppose, a test of their understanding of adding fractions. That the whole thing is itself in a fraction is presumably just to make the question seem harder. It shouldn’t really make the question any harder, but I suppose under pressure in an exam it does. The obvious thing to do is to multiply the fraction ‘top and bottom’ by xy. This gives:

The fact the 3 and 7 were chosen, which sums to 10, makes the question easier if it wanted an answer as a decimal expansion. Presumably an answer as a fraction would be acceptable too.
Let us skip the second part for a moment and head to the third. Clearly the values of p and q do not matter here, as they are cancelled out. The answer is hence merely 3. If for whatever reason you do not notice this, you have a lot of calculating to do! Nevertheless, it is a simple factorisation and will certainly be tested in more modern exams.
Going back to the second part – it is a pain really. Log tables are the easiest solution within the rules of the exam. Rather than find any particular shortcut, it is easier to ‘just do it’. Find the log of p, double it, anti-log it. Do the same with q. Add the two numbers together. Log it. Half it. Anti-log it. Then we got the answer. It’s boring, and how is it any better than using a calculator? All you are doing is looking some numbers up in a table and occasionally adding or halving them. It’s just a procedure. Perhaps it was useful then, but it isn’t useful now.
The first question, from the 1931 School Certificate, I actually like quite a bit. Let us do the third part first, as it the easiest. It is well known that 1/3 = 0.333…, and that 1/100 = 0.01. Thus 1/200 = 0.005. It follows that:

Now let us go back to the first part. We wish to find find the decimal expansion of 7/22. (Note that 22/7 is a popular approximation of pi, which comes from the continued fraction expansion of the number. 7/22 is also the approximation from the first three terms in the continued fraction expansion of 1/pi)
We could just use long division and not think about what we are doing, but I prefer to do these calculations more explicitly. To find the first decimal place of 7/22, we can multiply it by 10 and then take the integer part. This gives 70/22 = 3 + 4/22. Hence it starts 0.3. We then continue with 4/22 – multiply by 10 and take the integer part. This will clearly give the next decimal place. Now 40/22 = 1 + 18/22. Thus the expansion of 7/22 starts 0.31. Continue again: 180/22 = 8 + 4/22. Thus it continues 0.318. We have already seen 4/22, and hence it will yield a sequence continuing 1 then 8 forever. Hence the expansion is 0.318181818…, or 0.31818 to five decimal places.
The second part is unfortunately basically identical, and so is rather dull. We have:
- 710/223 = 3 + 41/223
- 410/223 = 1 + 187/223
- 1870/223 = 8 + 86/223
- 860/223 = 3 + 191/223
- 1910/223 = 8 + 126/223
- 1260/223 = 5 + 145/223
And hence the decimal expansion starts 0.318385, and so is 0.31839 to 5 decimal places.
Therefore our numbers are 0.31818, 0.31839 and 0.31833. The closest to the target number of 0.31831 is thus the third. (What were they playing at! 106/333 is much closer than all of them!)
Perhaps the third part is still useful today, but exactly evaluating the decimal expansions of fractions probably isn’t because of computers. So it is merely more modern.
It’s hard to say really which questions were harder. I didn’t like Part II of the second question as I couldn’t think of an easy way to do it. The other parts of the question were brainless however. The third question was interesting, but the first question was the most interesting, except for Part II which required you to do a load of arithmetic which was almost identical to what you had just done, which is boring. No wonder everybody hates maths.
I don’t have any solid conclusions myself. Indeed, when I was at school I looked through A-Level mathematics exams from the 1960s onwards. I actually thought the hardest papers were in the years 1990-1992. Previous years did not require you to understand anything, but just required you to ‘do’ things which could be learnt without understanding why. Later years were just easy. Happily, the exams I did myself were of the easy variety !
It is often said that people are worse at maths now than previous generations. Perhaps this is true, but I’m not entirely convinced previous generations were any good at it either. For instance, perhaps people who went to score in the 1970s can multiply and divide long integers, but in my experience from having seen people do it, they merely perform an algorithm they have learnt and never understand it. My calculator can do that, and it can do it better. When something goes wrong, they don’t know what they might have done wrong because they don’t know why it works. They might not remember what to do when they encounter a zero, etc.
Perhaps I will try and expand on this subject in future.





 gives Manchester United 38.1 points, but Manchester City 32.3.
gives Manchester United 38.1 points, but Manchester City 32.3.

 are one group of numbers with the property, then so is
are one group of numbers with the property, then so is  .
. have the property, then so do
have the property, then so do  , where K is a constant.
, where K is a constant. .
.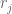 multiplied by a rational number. Write
multiplied by a rational number. Write ![[a_i]_j](https://s0.wp.com/latex.php?latex=%5Ba_i%5D_j&bg=ffffff&fg=555555&s=0&c=20201002) for the coefficient of
for the coefficient of ![[a_i]_j, 1 \le i \le 17](https://s0.wp.com/latex.php?latex=%5Ba_i%5D_j%2C+1+%5Cle+i+%5Cle+17&bg=ffffff&fg=555555&s=0&c=20201002) form a set of rational numbers with the property that taking out any one of them allows the remaining to be rearranged into two groups with the same sum. This is because the set of 17 real numbers have this property, and whatever the two sums are, the
form a set of rational numbers with the property that taking out any one of them allows the remaining to be rearranged into two groups with the same sum. This is because the set of 17 real numbers have this property, and whatever the two sums are, the 

 and
and  . Using these representations,
. Using these representations,

 for small x, we have:
for small x, we have:
 as required.
as required. . Let us write
. Let us write 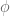 for
for  , and so the probability that they have a different birthday to everybody else is
, and so the probability that they have a different birthday to everybody else is  . In this case, the expected number of unique birthdays is 1+e(n-1). In the other case, which thus has probability
. In this case, the expected number of unique birthdays is 1+e(n-1). In the other case, which thus has probability  , the expected number is just e(n-1).
, the expected number is just e(n-1).


 . Thus the maximum must be around this, and so for all but the smallest D (where the approximation is not valid), the maximum will be either D-1 or D.
. Thus the maximum must be around this, and so for all but the smallest D (where the approximation is not valid), the maximum will be either D-1 or D.
 . Hence if
. Hence if  we must have:
we must have:
 so that:
so that:

 is the ratio between what you pay the worker per year, and what he earns for you per year if he were to work every day. Let us call this ratio P.
is the ratio between what you pay the worker per year, and what he earns for you per year if he were to work every day. Let us call this ratio P. always has a unique solution. The function which takes z to w is called the ‘
always has a unique solution. The function which takes z to w is called the ‘

 . Along with the usual log approximation, this gives:
. Along with the usual log approximation, this gives:

