Keypads with paint on the buttons
March 8, 2020 1 Comment
Near my home there is a door that is opened by a keypad. I know that it uses a four-digit code, where the order matters, but I don’t know what the code is.

An example of a keypad
When I walked past it the other day I noticed that there were blue fingerprints over three of the numbers on the keypad, but I did not look very closely and therefore there may have been four. If there were only three numbers with fingerprints on them then I would infer that one of the numbers in the code was repeated.
I wondered this: If I wanted to guess the code as quickly as possible would I prefer that there were three digits or four digits with paint on them?
Intuitively, most people (at least in my informal survey) seemed to expect that it is more constrained when there are only three digits, and so there are fewer combinations. After all, if there was only one blob of paint, so all the digits were the same, then there would be only one possible combination, so you may expect that each digit adds more freedom and thus more combinations.
In fact, this is not the case, and you would be better placed to guess the code if you knew it had four different digits.
The number of combinations to try if you know there are four different digits is of course ![]() . If instead it is known there are only three different digits in the code then one of them is repeated. To calculate the number fo combinations, imagine choosing the two positions in the 4-digit code that are the same digit – there are 6 (i.e. 4C2) ways to do this – and then choose which digit is the one which is repeated – there are 3 to choose from. The remaining 2 digits can be arranged in 2 ways – therefore there are
. If instead it is known there are only three different digits in the code then one of them is repeated. To calculate the number fo combinations, imagine choosing the two positions in the 4-digit code that are the same digit – there are 6 (i.e. 4C2) ways to do this – and then choose which digit is the one which is repeated – there are 3 to choose from. The remaining 2 digits can be arranged in 2 ways – therefore there are ![]() ways of doing it – 50% more!
ways of doing it – 50% more!
I thought this was somewhat surprising.
In general, suppose the painted key-pad buttons are ![]() and the lock takes an M digit code. Of course,
and the lock takes an M digit code. Of course, ![]() .
.
I think it is easier at this point to reason if we forget about locks and talk about functions instead. A function ![]() is equivalent to a possible code if it is surjective. The code it represents is
is equivalent to a possible code if it is surjective. The code it represents is ![]() . As f is surjective every painted digit appears at least once, as is required.
. As f is surjective every painted digit appears at least once, as is required.
We can therefore restate the problem as counting the number of surjective functions from {1,2,…,M} to {1,2,…,N}.
It’s easy to find out the number of functions if we drop the ‘surjective’ requirement – it is NM. This number includes non-surjective functions – where the image of the function is some proper subset of {1,2,…,N} – as well. An inclusion-exclusion argument can be used to calculate the number of surjections.
In particular, define cito be the number of functions f from {1,2,…,M} to {1,2,…,N} such that at least i of elements of {1,2,…,N} are missing from the image of f (i.e. the image of f is at most N-i).Ci is then easy to calculate – choose the i elements to exclude (there are NCi of them) and then assign to each f(j) one of the possible remaining N-i values. Repeat that for all M function inputs and hence:
![]()
Then, by inclusion-exclusion, the number of surjective functions is:
![]()
And hence the number of surjections, and hence the number of possible lock codes of length M using N different digits, each at least once, is:
![]()
This is related to Stirling Numbers of the Second Kind.
Not all keypads use four-digit codes. Looking online, most digital keypad locks can use between 1 and 12 digit codes. The following chart shows the approximate number of combinations that are possible if the length of the code is known (the number on the left-hand side) and the number of painted digits is known (the number on the top):

(Here a million is 106 and a billion is 109)
In reality, you may not know the number of digits in the code. Here is the number of combinations that must be tried if you know an upper-bound to the number of digits in the code:

A few additional thoughts:
- Many digital keypads also require a card to be presented and the code is associated with the particular card (i.e. is a PIN). Then you will need access to the card too.
- Most mechanical keypads, disappointingly, don’t actually require the digits to be entered in any particular order.
- There exist keypads that randomise the digits every time they are used. In addition, they can use special screens that can only be seen when looking straight at them.
- You may be tempted to think that the repeated digit, if there was one, might have more paint on it. However, it actually turns out that the first button pressed deposited much more paint on it than the others. By way of an example, if you are looking for a four-digit code and there are three paint splodges, then by identifying the first digit you reduce the 36 combinations to 12 (not 6, as the first digit may have also been the repeated digit).


 are one group of numbers with the property, then so is
are one group of numbers with the property, then so is  .
. have the property, then so do
have the property, then so do  , where K is a constant.
, where K is a constant. .
.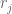 multiplied by a rational number. Write
multiplied by a rational number. Write ![[a_i]_j](https://s0.wp.com/latex.php?latex=%5Ba_i%5D_j&bg=ffffff&fg=555555&s=0&c=20201002) for the coefficient of
for the coefficient of ![[a_i]_j, 1 \le i \le 17](https://s0.wp.com/latex.php?latex=%5Ba_i%5D_j%2C+1+%5Cle+i+%5Cle+17&bg=ffffff&fg=555555&s=0&c=20201002) form a set of rational numbers with the property that taking out any one of them allows the remaining to be rearranged into two groups with the same sum. This is because the set of 17 real numbers have this property, and whatever the two sums are, the
form a set of rational numbers with the property that taking out any one of them allows the remaining to be rearranged into two groups with the same sum. This is because the set of 17 real numbers have this property, and whatever the two sums are, the 

 . Suppose we wish u = 60. Then we have that
. Suppose we wish u = 60. Then we have that  . Note that there is no value of v2 that makes this true!
. Note that there is no value of v2 that makes this true! . Let us write
. Let us write 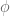 for
for  , and so the probability that they have a different birthday to everybody else is
, and so the probability that they have a different birthday to everybody else is  . In this case, the expected number of unique birthdays is 1+e(n-1). In the other case, which thus has probability
. In this case, the expected number of unique birthdays is 1+e(n-1). In the other case, which thus has probability  , the expected number is just e(n-1).
, the expected number is just e(n-1).


 . Thus the maximum must be around this, and so for all but the smallest D (where the approximation is not valid), the maximum will be either D-1 or D.
. Thus the maximum must be around this, and so for all but the smallest D (where the approximation is not valid), the maximum will be either D-1 or D.
 . Hence if
. Hence if  we must have:
we must have:
 so that:
so that:

 is the ratio between what you pay the worker per year, and what he earns for you per year if he were to work every day. Let us call this ratio P.
is the ratio between what you pay the worker per year, and what he earns for you per year if he were to work every day. Let us call this ratio P. always has a unique solution. The function which takes z to w is called the ‘
always has a unique solution. The function which takes z to w is called the ‘

 . Along with the usual log approximation, this gives:
. Along with the usual log approximation, this gives:

 elements in this probability space.
elements in this probability space.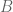 . Similarly, let us denote the event that there are exactly
. Similarly, let us denote the event that there are exactly 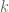 pairs of people who are sharing a birthday (and no triplets or higher) as
pairs of people who are sharing a birthday (and no triplets or higher) as  .
. or
or  or
or  happens. That is,
happens. That is,

 .
. ). Then we will have over-counted, because the pairs are in an ordered list. For instance, suppose we picked the ordered list of unordered pairs “Person 1 & Person 2”, “Person 3 & Person 4”. Then we selected the ordered list of birthdays “1st Jan, 2nd Jan”. Then this would give us the same thing as if we’d selected the pairs “Person 3 & Person 4”, “Person 1 & Person 2” with the list of birthdays “2nd Jan, 1st Jan”. In this case we over counted by a factor of 2. In general, we will overcount by the number of permutations of the list of pairs. This is
). Then we will have over-counted, because the pairs are in an ordered list. For instance, suppose we picked the ordered list of unordered pairs “Person 1 & Person 2”, “Person 3 & Person 4”. Then we selected the ordered list of birthdays “1st Jan, 2nd Jan”. Then this would give us the same thing as if we’d selected the pairs “Person 3 & Person 4”, “Person 1 & Person 2” with the list of birthdays “2nd Jan, 1st Jan”. In this case we over counted by a factor of 2. In general, we will overcount by the number of permutations of the list of pairs. This is  .
. people can have any remaining birthday. So the first has a choice of
people can have any remaining birthday. So the first has a choice of  , the next a choice of
, the next a choice of  and so forth. Therefore,
and so forth. Therefore,
 is the probability that at least two people will share a birthday in a group of N people. Remember that
is the probability that at least two people will share a birthday in a group of N people. Remember that  .
. . There is no obvious closed form expression for it, so it will suffice to numerically calculate it for the desired values. Doing so yields the following graph:
. There is no obvious closed form expression for it, so it will suffice to numerically calculate it for the desired values. Doing so yields the following graph:


 pence and
pence and  ). That we have:
). That we have:

 . It hence the follows that:
. It hence the follows that:
 . By choice of k, this is equal to
. By choice of k, this is equal to  . It follows that
. It follows that  as if there were 116 items the cost would be at least 99×116 = £114.84. Given that it is less than this at £35.84, we be sure that there are only 16 items. This also answers the second part – you cannot tell, there could be 16 or 116 items in your basket.
as if there were 116 items the cost would be at least 99×116 = £114.84. Given that it is less than this at £35.84, we be sure that there are only 16 items. This also answers the second part – you cannot tell, there could be 16 or 116 items in your basket. items. However, if there 88 items that must cost at least £87.12, and so there is no way that this total could be achieved.
items. However, if there 88 items that must cost at least £87.12, and so there is no way that this total could be achieved. . Then the problem is to find a natural number x such that
. Then the problem is to find a natural number x such that  .
. .
. and
and  , where x is a d digit number (in base b). Thus we are attemping to solve:
, where x is a d digit number (in base b). Thus we are attemping to solve:

 . However, as
. However, as  it follows that this is equivelent to:
it follows that this is equivelent to:
 . In particular, valid values of d must be of the form
. In particular, valid values of d must be of the form  .
. and
and  , where the digit concatenations are in base b. Let us also define S to be s digits long (in base b) and R to be r digit long (in base b).
, where the digit concatenations are in base b. Let us also define S to be s digits long (in base b) and R to be r digit long (in base b). and
and  (where in fact
(where in fact  ).
). :
:![T:1 = (S:1) + (R:1) b^{s+1} = k(1:S) + kb^{s+1} (1:R) = k[(1:s) + (1:R)b^{s+1}] = k(1:S:1:R) = k(1:T)](https://s0.wp.com/latex.php?latex=T%3A1+%3D+%28S%3A1%29+%2B+%28R%3A1%29+b%5E%7Bs%2B1%7D+%3D+k%281%3AS%29+%2B+kb%5E%7Bs%2B1%7D+%281%3AR%29+%3D+k%5B%281%3As%29+%2B+%281%3AR%29b%5E%7Bs%2B1%7D%5D+%3D+k%281%3AS%3A1%3AR%29+%3D+k%281%3AT%29&bg=ffffff&fg=555555&s=0&c=20201002)
 . Notice how, as expected, this is still of the required form.
. Notice how, as expected, this is still of the required form.

